Current Research
Towards CPU-free datamovement in the cloud
In my current work, I'm exploring new hardware and software technologies to enable fast, reliable, low-overhead, and secure communication in datacenters. I'm working towards designing of completely CPU-free cloud networking stacks, where the entire cross-machine application-to-application data path runs outside of the processor, with zero software overhead and CPU utilization.My general philosophy here is that datacenter processors should not waste their time and energy for data exchange, especially at 400 Gbps and beyond. This is particularly important in the today’s world of fine-granular, highly-concurrent, and interactive internet services, especially the ones based on the pay-as-you-go cost model. CPU-free communication stacks will dramatically reduce the total amount of CPU time required per application, and will also enable truly nano-second scale cloud networking. Just imagine your microservices where there is almost no difference in calling remote vs local functions. Physically, this is already possible today with all the advances in datacenter optical wiring and switching. We just needs to sort out the bottlenecks in the end-host, so here we go!
In addition to this main research direction, I also worked (in collaboration with Microsoft Azure for Operators) on cloud native 5G architectures and virtual radio access networks (vRAN) with the focus on resilience and fault tolerance.
These days, I’m a visiting researcher at Google NYC.
Projects
Dagger: CPU-Free End-Host RPC Stack
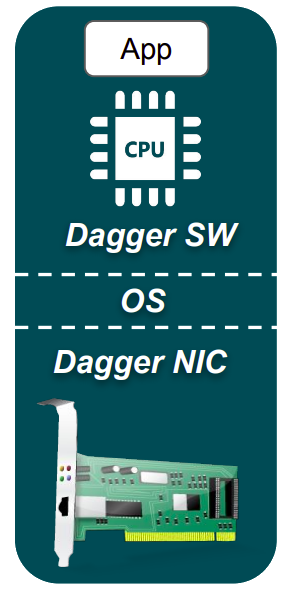
In this project, we built the first proof-of-concept system for offloading a basic cloud RPC stack to cache-coherent FPGAs. Our FPGA-based SmartNIC runs the end-to-end RPC datapath in hardware, and communicates ready-to-use user-level objects directly with the application memory at low latency and high CPU efficiency. The latter is achieved via tight integration of the FPGA with the host processor over a NUMA interconnect. This essentially enables the shared-memory model of communication between applications and hardware, therefore bypassing the OS kernel, device drivers, and any other software layers. Advisors: Professor Zhiru Zhang and Professor Christina Delimitrou.
ASPLOS’21 Conference Talk, 2021
IEEE CAL Early Work Paper, 2020
Towards Virtual Radio Access Networks (vRAN) as Cloud Native Feature

5G networks come with great bandwidth and low latency, therefore enabling many emerging applications such as self-driving cars, drone swarms, IoT, cloud gaming, and so on at the large scale. However, in order to take the full advantage of their potential, networking functions for 5G and beyond must be scalable, reliable, and intelligently adaptable. This research aims to develop novel technologies to address the aforementioned requirements and enhance the widespread adoption of radio access networks. In particular, we further extend the concept of vRAN to introduce fault tolerance, disaggregation, and load balancing when deploying 5G network functions on the edge cloud platforms at scale.
This work is a collaborative effort with Microsoft Azure for Operators Research group at Microsoft.
Mentor: Anuj Kalia.
SIGCOMM’23 Paper on 5G PHY Resilience, 2023
SIGCOMM’23 Conference Talk, 2023
Sabre: Hardware-Accelerated Snapshot Compression for Serverless MicroVMs

MicroVM snapshotting significantly reduces the cold start overheads in serverless applications. Snapshotting enables storing part of the physical memory of a microVM guest into a file, and later restoring from it to avoid long cold start-up times. Prefetching memory pages from snapshots can further improve the effectiveness of snapshotting. However, the efficacy of prefetching depends on the size of the memory that needs to be restored. Lossless page compression is therefore a great way to improve the coverage of the memory footprint that snapshotting with prefetching achieves. Unfortunately, the high overhead and high CPU cost of software-based (de)compression makes this impractical.
We introduce Sabre, a novel approach to snapshot page prefetching based on hardware-accelerated (de)compression. Sabre leverages an increasingly pervasive near-memory analytics accelerator available in modern datacenter processors. We show that by appropriately leveraging such accelerators, microVM snapshots of serverless applications can be compressed up to a factor of 4.5×, with nearly negligible decompression costs.
The project is sponsored by Intel Labs.
